High-Performance AI Processors to Transform The Digital World
- Rana Udayveer Singh
- Jul 22, 2021
- 7 min read
Updated: Sep 11, 2023
Artificial Intelligence has brought a revolutionary change in every aspect of our lives in this era of technology. When we see autonomous cars, smartphones, electronic devices, or robotics around us, we can witness a glimpse of the opportunities created by incorporating AI. Besides, new generation AI processors are much more powerful, and tasks like image processing, machine vision, machine learning, deep learning, and artificial neural networks can be done more efficiently. The list of top AI chip manufacturers includes Tencent, Samsung Electronics, and LG Electronics in this industry which also establish themselves as key contenders in the AI chip market. So, we would not be wrong to assume that the involvement of the leading tech giants will definitely propel the growth of AI technologies to a great extent in the coming years. The core processor architectures that are commonly used in AI systems are divided into three categories, i.e., Scalar, Vector, and Spatial.
What is an AI (Artificial Intelligence) Processor?
An AI (Artificial Intelligence) processor, also known as an AI accelerator or AI chip, is a specialized hardware component designed to perform AI-related tasks more efficiently than traditional general-purpose processors (e.g., CPUs or GPUs). These processors are optimized to handle the computational workloads involved in machine learning and deep learning applications, which often involve tasks like neural network training and inference.

Characteristics and Functions of AI Processors
Parallel Processing: AI processors are typically designed with a high degree of parallelism, allowing them to execute multiple AI-related calculations simultaneously. This parallelism is well-suited for the matrix multiplication and vector operations commonly used in neural network computations.
Reduced Precision: Many AI processors use reduced-precision arithmetic (e.g., 8-bit or 16-bit) to perform calculations. This helps improve both computational efficiency and power efficiency while maintaining acceptable levels of accuracy for AI tasks.
Hardware Optimization: AI processors often incorporate hardware components and instructions specifically tailored for AI workloads. These may include specialized multiply-accumulate (MAC) units, on-chip memory, and instructions for neural network operations.
Energy Efficiency: Energy efficiency is crucial in AI applications, especially in mobile devices and edge computing scenarios. AI processors are designed to provide high computational power while minimizing energy consumption.
Neural Network Support: AI processors are optimized for tasks related to neural networks, such as forward and backward passes during training and inference. They may also support various neural network architectures and frameworks.
Integration: AI processors can be integrated into various devices, including smartphones, edge devices, data center servers, and even autonomous vehicles. They are often used alongside traditional CPUs and GPUs to offload AI-specific workloads.
Examples of AI processors and chip architectures include NVIDIA's Tensor Processing Units (TPUs), Google's Edge TPU, Intel's Nervana Neural Network Processors (NNPs), and many others. These processors have been instrumental in accelerating the development and deployment of AI applications in a wide range of industries, from healthcare and automotive to finance and entertainment.
Processors Used In AI Systems
Scalar (CPUs)
A modern CPU is designed to perform well at a wide variety of tasks, for instance, it can be programmed as a SISD machine to give output in a certain order. However, each CISC instruction gets converted to a chain of multiple RISC instructions for execution on a single data element (MISD). It will look at all the instructions and data that we feed and it will line them up in parallel to execute data on many execution units (MIMD). Also, with multiple cores and multiple threads running in parallel to use resources simultaneously on a single core, almost any type of parallelism can be implemented.
If a CPU were to operate in a simple SISD mode, grabbing each instruction and data element one at a time from memory, it would be exceptionally slow, no matter how high the frequency is clocked at. In a modern processor, only a relatively small portion of the chip area is dedicated to actually performing arithmetic and logic. The rest is dedicated to predicting what the program will do next, and lining up the instructions and data for efficient execution without violating any causality constraints. Therefore, conditional branching is most relevant to the CPU’s performance versus other architectures. Instead of waiting to resolve a branch, it predicts which direction to take, and then completely reverts the processor state if it is wrong.
Vector (GPUs and TPUs)
A vector processor is the simplest modern architecture with a very limited computation unit that is repeated many times over the chip to perform the same operation over a wide array of data. The term Graphical Processing Unit is most commonly used these days because initially, these became popular for their use in graphics. A GPU specifically has a limited instruction set to only support certain types of computation. Most of the advancement in GPU performance has come through basic technological scaling of density, area, frequency, and memory bandwidth.

Image Source: https://insujang.github.io/2017-04-27/gpu-architecture-overview/
General Purpose Computing on Graphics Processing Unit (GPGPU)
Recently, there has been a trend to expand the GPU instruction set to support general-purpose computing. These instructions must be adapted to run on the SIMD architecture and its algorithms run as a repeated loop on a CPU and perform the same operation on each adjacent data element of an array in every cycle. GPUs have very wide memory buses that provide excellent streaming data performance, but if the memory accesses are not aligned with the vector processor elements, then each data element requires a separate request from the memory bus. GPGPU algorithm development is, in the general case, much more difficult than for a CPU.
Artificial Intelligence
Many Artificial Intelligence algorithms are based on linear algebra, and a massive amount of development in this field has been done by expanding the size of parameter matrices. The parallelism of a GPU allows for massive acceleration of the most basic linear algebra, so it has been a good fit for AI researchers, as long as they stay within the confines of dense linear algebra on matrices that are large enough to occupy a big portion of the processing elements, and small enough to fit in the memory of the GPU. The two main thrusts of modern development in GPUs have been toward tensor processing units (TPUs), which perform full matrix operations in a single cycle, and Multi- GPU interconnects to handle larger networks. Today, we experience great divergence between the hardware architectures for dedicated graphics, and hardware designed for AI, especially in precision.

Image Source: https://semiengineering.com/knowledge_centers/integrated-circuit/ic-types/processors/tensor-processing-unit-tpu/
Spatial (FPGAs)
An FPGA can be designed for any type of computing architecture, but here we focus on AI-relevant architecture. In a clocked architecture such as a CPU or GPU, each clock cycle loads a data element from a register, moves the data to a processing element, waits for the operation to complete, and then stores the result back to the register for the next operation. In a spatial data flow, the operations are directly connected to the processor so that the next operation executes as soon as the result is computed, and thus, the result is not stored in any register.
They have some advantages that are easily realized in terms of Power, Latency, and Throughput. In a register-based processor, power consumption is mostly due to data storage and transport to and from the registers. This is eliminated, and the only energy expended is in the processing elements, and transporting data. The other main advantage is the latency between elements, which is no longer limited to the clock cycle. There are also some potential advantages in throughput, as the data can be clocked into the systolic array at a rate limited only by the slowest processing stage. The data clocks out at the other end at the same rate, with some delay in between, which establishes the data flow. The most common type of systolic array for AI implementations is the tensor core, which has been integrated into a synchronous architecture as a TPU or part of a GPU. Full data flow implementations of entire deep learning architectures like ResNet-50 have been implemented in FPGA systems, which achieved state-of-the-art performance in both latency and power efficiency.
When choosing an AI processor for a particular system, it is important to understand the relative advantages of each within the context of the algorithms used and the system requirements and performance objectives.

Image Source: https://iq.opengenus.org/cpu-vs-gpu-vs-tpu/
The global AI chip market is currently valued at around $9 billion but is estimated to grow up to around $90 billion in the next four years and around $250 by 2030, at a CAGR of 35%, according to a study by Allied Market Research. There are many companies out there that have been successful in holding large chunks of the marketplace of AI Processors. Now, to get a brief idea of the current AI chip market, we have listed some top companies in this sector.
Top 10 Patent Assignee - AI Processor

Top Patent Application Countries - AI Processor
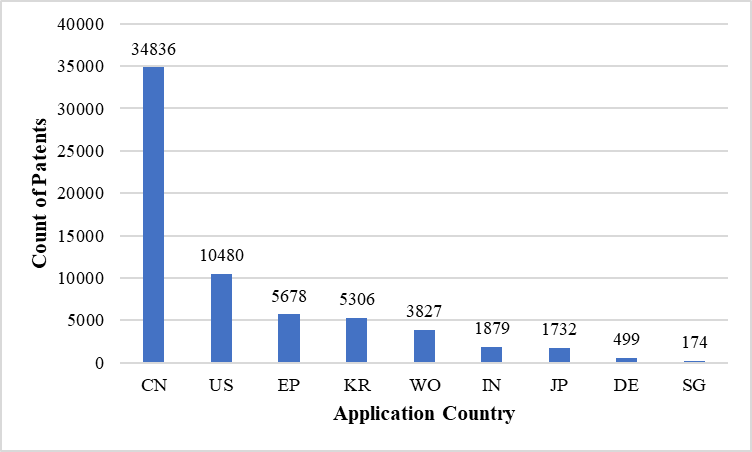
China's dominance in patent filings for artificial intelligence (AI) processors can be attributed to its combination of government support, a large market and consumer base, an evolving intellectual property strategy, strong manufacturing capabilities, and fruitful collaborations between academia and industry. The Chinese government's initiatives and investments in AI technology, such as the "Made in China 2025" program, have incentivized companies and researchers to innovate and file patents. China's robust manufacturing capabilities and collaborations between academia and industry further contribute to its leadership in patent filings for AI processors.
Patent Filing Trend - AI Processor

The year 2021 experienced a peak in patent filings in the field of AI due to a combination of factors. The rapid technological advancements in AI, particularly in areas like machine learning and computer vision, have spurred increased research and innovation. Simultaneously, the growing market demand for AI solutions across industries has intensified competition among companies, leading them to protect their inventions through patents. Lastly, the evolving policy and regulatory landscape surrounding AI has prompted companies to secure their intellectual property rights through patent filings to navigate the legal and commercial aspects of AI technology.
Conclusion
Artificial Intelligence is the future of technology. You can’t expect to find a single device that does not come with AI capabilities in the near future. As a result, all the leading companies invest and research more to establish a strong position in the ongoing war in the AI Chip Market. Besides, ML and DL also play an important role in making AI more powerful and improving performance to a great extent. As mentioned above, companies bring AI processors every year, which has made it easy for manufacturers to bring AI to the edge of the data centers. It does not matter which company leads the race, the consumers will benefit in every case.
References
Keywords:
ai processor, processor, cpu, gpu, tpu, intel xeon, titan rtx, rtx 3080, ryzen 7 3700x, amd ryzen, gtx 1070, intel core i5, ryzen 9 3900x, intel core i7, nvidia geforce rtx 3080, intel core i9, gaming graphics card, graphics card, gpu z, amd radeon, artificial intelligence, machine learning, deep learning, fpga
Comentarios